
Spring & Java
자료구현 알고리즘 (1) 본문
문제를 충분히 이해하는데 시간을 쓰자.
● 무작정 코드를 짜기 보다 문제의 의도를 파악하고 풀이를 위해 단계별로 접근하자!
※ 학습 태도 갖추기
다양한 풀이 방식을 시도하기 - 같은 문제도 다른 알고리즘이나 자료구조를 적용해보며, 사고의 폭을 넓힙니다.
문제 해결 과정을 설명하기 - 풀이 방식을 외우는 것보다, 문제를 푸는 과정을 논리적으로 이해하고 표현하는 것이 핵심
나만의 알고리즘 노트 만들기 - 알고리즘 문제에 대해 나의 풀이 과정을 정리하기!
알고리즘 개념
● 알고리즘 정의를 이해하고 좋은 알고리즘의 특성을 설명할 수 있다.
● 알고리즘의 성능 측정을 위해 시간 복잡도의 개념을 이해하고 계산할 수 있다.
● 문제 해결을 위해 알고리즘을 자연어로 표현할 수 있다.
알고리즘 : 문제를 해결하기 위한 단계적 절차나 규칙
코딩 문제의 알고리즘 예시
< 장바구니 합계 계산 알고리즘 >
1단계: 장바구니 상품 목록을 입력받는다
2단계: 총 금액 변수를 0으로 설정
3단계: 각 상품에 대해 반복:
- 상품의 가격 × 수량을 계산
- 계산 결과를 총 금액에 더함
4단계: IF 총 금액이 50,000원 이상이면
배송비 = 0
ELSE
배송비 = 3,000
5단계: 최종 결제 금액 = 총 금액 + 배송비
6단계: 최종 결제 금액 출력
알고리즘 성능 분석
알고리즘 성능 분석이란 무엇일까요?
❗알고리즘 성능 분석이란?
알고리즘이 얼마나 효율적으로 동작하는지를 측정하는 방법입니다.
주로 시간(실행 속도)과 공간(메모리 사용량)을 기준으로 평가합니다.
알고리즘의 성능을 분석할 때 가장 중요하게 살펴보아야 할 것이 바로 시간복잡도입니다.
시간복잡도는 알고리즘이 문제를 해결하는데 얼마나 많은 시간이 필요한지를 표현하는 방법으로,
주로 빅오(Big-O) 표기법을 사용하여 나타냅니다.
시간복잡도는 프로그램의 응답 시간과 직결됩니다
예: SNS 피드 로딩이 10초 이상 걸린다면, 사용자들은 앱을 이탈할 가능성이 높습니다
반면 공간복잡도(메모리 사용)는 사용자가 직접 체감하기 어렵습니다
빅오 ( Big - O ) 표기법 뭔가요?
❗
빅오 표기법은 알고리즘의 시간 복잡도를 수학적으로 표현한 방법입니다.
주로 입력 데이터의 크기가 늘어날 때 알고리즘의 실행 시간이 어떤 비율로 증가하는지를 표현합니다.
즉, 정확한 실행 시간이 아닌, 입력 데이터의 크기에 따라서 실행 시간의 증가 추세를 표현합니다.
시간 복잡도 구하기
1. 명령문 개수 계산
● 반복문, 조건문, 대입문 등 각각의 명령문이 실행되는 횟수를 계산합니다.
● 각 줄의 실행 횟수를 더하여 전체 실행 횟수를 구합니다.
public class TimeComplexityExamples {
/**
* O(1) - 상수 시간 복잡도
* 입력값 n에 상관없이 항상 동일한 시간이 걸립니다.
* 단순 출력문 하나만 실행되므로 실행 시간이 일정합니다.
*/
public void constantTime(int n) {
System.out.println(n); // 단 한 번의 연산만 수행
}
/**
* O(n) - 선형 시간 복잡도
* 입력값 n에 비례하여 실행 시간이 증가합니다.
* n이 2배가 되면 실행 시간도 약 2배가 됩니다.
*/
public void linearTime(int n) {
for(int i = 0; i < n; i++) {
System.out.println(i); // n번 실행됨
}
}
/**
* O(n²) - 제곱 시간 복잡도
* 입력값 n의 제곱에 비례하여 실행 시간이 증가합니다.
* n이 2배가 되면 실행 시간은 4배가 됩니다.
*/
public void quadraticTime(int n) {
// 외부 루프: n번 반복
for(int i = 0; i < n; i++) {
// 내부 루프: 각 i에 대해 n번 반복
for(int j = 0; j < n; j++) {
System.out.println(i + j); // n * n = n² 번 실행됨
}
}
}
}
2. 가장 큰 항만 남기기
빅오 표기법에서는 가장 영향력이 큰 항만 고려하는 이유
1. 입력 크기 (n) 가 매우 커질 때는 작은 항들의 영항력이 미미해지기 때문입니다.
2. 상수항은 실제 실행 환경에 따라 달라질 수 있어서 제외합니다
3. 증가 추세를 파악하는 것이 목적이므로 정확한 횟수보다는 전체적인 증가 패턴이 중요합니다.
예시 : 입력 데이터 크기가 n일 때 명령어 실행횟수가 T(n)인 경우 시간 복잡도 계산
T(n) = 5n³ + 100n² + 200n + 1000
단순화 과정
1. 최고차항 선택: 5n³
2. 계수 제거: n³
3. 다른 항 제거: n², n, 상수항 제거
4. 최종 표기: O(n³)
예시 코드
/* 1부터 n까지의 합을 구하는 알고리즘
실행 횟수 분석 및 시간 복잡도 계산 */
int sum = 0; // 초기화: 대입 연산 1회
/* 반복문 실행 분석
- 초기화 (i = 0): 대입 연산 1회
- 조건 검사 (i < n): 조건 연산 n+1회
- 증감식 (i++): 증감 연산 n회 */
for(int i = 0; i < n; i++) {
sum += i; // 덧셈 연산 n회
}
System.out.println(sum); // 출력: 함수실행 1회
/* 전체 실행 횟수 계산
= 1 + 1 + (n+1) + n + n + 1
= 3n + 4
시간 복잡도: O(n)
- 실행 횟수가 n에 비례하여 선형적으로 증가 */
무엇이 더 좋은 알고리즘 일까요?
같은 시간 복잡도 일까요?
배열의 모든 원소의 합과 최대값을 구하기 위해 반복문을 한번만 사용하는 것과 반복문을 두번 사용하는 것과의 시간 복잡도 차이가 있을까요?
public class SimpleTimeComplexity {
public static void main(String[] args) {
int n = 10000;
int[] numbers = new int[n];
// 배열 초기화
for (int i = 0; i < n; i++) {
numbers[i] = i + 1;
}
// 방법 1: 하나의 반복문으로 두 연산 수행
System.out.println("방법 1: 하나의 반복문");
int sum1 = 0;
int max1 = 0;
for (int i = 0; i < n; i++) {
sum1 += numbers[i]; // 합계 구하기
if (numbers[i] > max1) {
max1 = numbers[i]; // 최댓값 찾기
}
}
// 방법 2: 두 개의 반복문으로 각각 연산 수행
System.out.println("방법 2: 두 개의 반복문");
int sum2 = 0;
for (int i = 0; i < n; i++) {
sum2 += numbers[i]; // 합계 구하기
}
int max2 = 0;
for (int i = 0; i < n; i++) {
if (numbers[i] > max2) {
max2 = numbers[i]; // 최댓값 찾기
}
}
}
}
두 방법은 실행시간에 차이가 있지만 시간 복잡도 O(n)으로 같습니다.
● 두 방법에서 배열의 합과 최대값을 구하기 위해 실제로 수행되는 핵심 연산들 ( 배열 접근, 덧셈, 비교, 할당) 의 횟수가 동일합니다.
● 유일한 차이점은 방법 2에서 반복문의 초기화 (i=0), 조건 검사 ( i < n ), 증감 연산 ( i++ ) 이 한 번더 실행된다는 것 뿐입니다.
따라서 과도하게 하나의 반복문에 모든 로직을 처리할 필요는 없고, 코드의 가독성과 유지보수성을 고려하여 각 기능( 합계 계산, 최대값 찾기) 을 논리적으로 분리하는 것이 바람직할 수 있습니다.
1부터 1000까지의 합을 구하는 알고리즘 비교
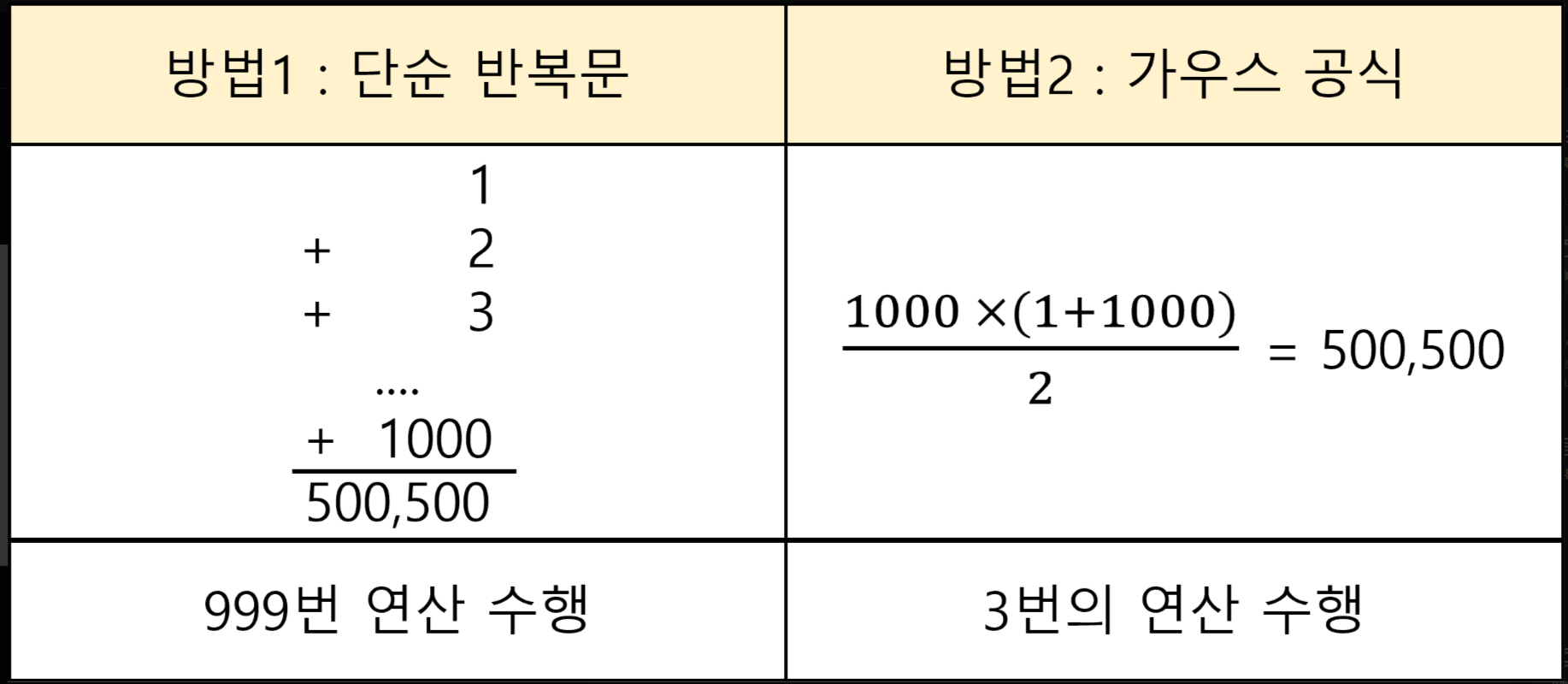
public class SumAlgorithms {
// 방법 1: 단순 반복문 - O(n)
public static int sumLoop(int n) {
int total = 0;
for (int i = 1; i <= n; i++) {
total += i;
}
return total;
}
// 방법 2: 가우스 공식 - O(1)
public static int sumGauss(int n) {
return n * (n + 1) / 2;
}
public static void main(String[] args) {
int n = 1000;
// 각 방법의 실행 시간 측정을 위한 변수
long startTime, endTime;
// 방법 1: 반복문
startTime = System.nanoTime();
int result1 = sumLoop(n);
endTime = System.nanoTime();
System.out.println("반복문 결과: " + result1);
System.out.println("실행 시간: " + (endTime - startTime) + " ns");
// 방법 2: 가우스 공식
startTime = System.nanoTime();
int result2 = sumGauss(n);
endTime = System.nanoTime();
System.out.println("\n가우스 공식 결과: " + result2);
System.out.println("실행 시간: " + (endTime - startTime) + " ns");
}
}
Big-O시간복잡도에 따른 실제 실행 시간 비교표
실제 수행 시간은 하드웨어 사양(CPU, 메모리 등), 운영체제, 프로그래밍 언어,
컴파일러 최적화 등 다양한 요인에 따라 달라질 수 있습니다.
'자료구조 및 알고리즘' 카테고리의 다른 글
| 완전탐색과 그리디 알고리즘 (2) (0) | 2025.12.23 |
|---|